 Joel Lieser
Joel LieserDisclosure: All opinions expressed in this article are my own, and represent no one but myself and not those of my current or any previous employers.
I've been playing quite a bit with generative AI and the technologies that have blossomed in the orbit of it (like vector databases) for coming up on a year and a half, by the time the (unlucky) reader finishes this blog. This is both a reflection of when I started focusing my time on it as well as my unfortunate inability for brevity.
Where I Think a Lot of Folks Get It Wrong
For many people at this infancy stage in the generative-ai wave, "AI" is ChatGPT. Or it's something else that acts like ChatGPT. On some level, the acronym AI conjures thoughts of some incarnation of a chat bot, but these new ones speak more elegantly, and also have a tendency to get racist and shit, which is different than that annoying fucking paperclip Windows thing that used to raise my blood pressure. That thing was like New Coke in the 1980s. Riiiiight, that one probably lands. Lots of 50-somethings reading this drivel, no doubt.

Here's my mental model, to keep things simple:
A LLM has been trained on massive, massive amounts of data. Internet data, books, sports stories, movie scripts, financial data, war stories, academic papers and encyclopaedias, to name a few sources.
Neural networks are used to make the LLM able to understand how to respond because it learns the language and the nuances of it. It is able to (incredibly impressively) predict the next word, and in doing so, creates sentences that make sense as responses to our inputs.
Let's just call this predict-the-next-word part the "British part." Mostly because it sounds really smart and beyond reproach, even when it's horribly wrong. Side note, it often does it annoyingly, which may or may not also have impacted my decision to call it the "British part."

Now, when someone asks you a question, like "how are you today?" it knows to respond with something like this:

This is a response based on how well it understands the English language. I mean...I might have nudged it to sound more British than it normally would, but you get the point. This is a language skill, and has nothing to do with information - or data - in the response. So this part is that it understands language, and how to respond. You know, the British part.
Then there is the other part of the response, which is the data, or information it includes in the response. These are the facts that it includes in that response. This is how when you ask it a question about past US Presidents, it is able to reference George Washington, Thomas Jefferson, Ben Franklin, and Barack Obama, for instance. It's the meat of the response. The answer. The data. The knowledge. The annals that it pulls from, if you will, we'll herein refer to as the "corpus." Also, I hope everyone reading this knows Ben Franklin wasn't a President.

Now, think about what you hear about AI as the reasons it sucks and will never be anything more than it is today: mostly, it's not trustworthy. It's the hallucinations. You cannot guarantee it isn't going to tell you the wrong answer. And the LLM absolutely will do that. But what does that really mean? It means that the data it uses from the corpus is either incorrect, or it messes it up. Maybe it does say that Franklin was a President, or maybe it gives you code that won't compile, or it depicts Nazis as Asians. Yikes on the last one.
It's kind of like listening to some of the right wing folks in my family try to explain how arming more "good guys" is the only way to stop gun violence in the United States, despite an entire globe full of contradictory data. They're reaching into their own corpus of information; data they've learned from, and pulling some out that is just blatantly wrong, or that they're mis-using (yes, I am aware that a lot of people die in bathtub accidents each year. No, that doesn't mean I think we should outlaw bath tubs. I don't see how that is relevant. Yes, this is a real conversation I've had to have). They're using their corpus (regardless of whether the data is right or wrong) and communicating it using their British part. I mean, to be fair, some of my family members are probably more likely to yell at a Brit "speak American!" than to sound British, but you get the point.
What I am saying is that if you are concerned about AI because the answers aren't right, I think you're doing it wrong, at least in the short to medium term. I think the right way to use AI (for MOST commercial applications) is to leverage the part of the LLM to respond (the British part), but to have it not use the corpus it was trained on to retrieve information, because that's where it goes sideways. So what the hell does that really mean, in practice?
Retrieval Augmented Generation (RAG)
Let's start with the easiest one, and the one that is increasingly more common every day, and that's Retrieval Augmented Generation, or RAG. I like this definition:
"In a RAG-based AI system, a retrieval model is used to find relevant information from existing information sources while the generative model takes the retrieved information, synthesizes all the data, and shapes it into a coherent and contextually appropriate response."
And I'll go a step further, using this reference:
"With RAG, we are performing a semantic search across many text documents — these could be tens of thousands up to tens of billions of documents.
To ensure fast search times at scale, we typically use vector search — that is, we transform our text into vectors, place them all into a vector space, and compare their proximity to a query vector using a similarity metric like cosine similarity."
Back to my words (look at me, look at me, look at me!): many of the RAG implementations you may have seen/used involve a vector database (VDB). These are databases that specialise in storing and retrieving numeric representations of non-numeric data, such as text, images, and video. RAG doesn't necessarily have to include vector databases (RAG is about fetching relevant context from a dataset to assist the generator in producing more accurate and relevant outputs), but because you often use embedding algorithms that align with the LLM you are going to use it with, there is a natural match there. I'm a huge proponent of vector databases, and one of the best things about the AI wave has been that vector databases have been given new life. But VDB is not an AI technology, to be clear. And RAG does not require VDB. But it's a good example, and the most common applications of RAG, at the time of this writing, include a VDB.
My point here is that RAG is a step in the direction of using a different corpus than the corpus that the LLM was built on (minimally, providing it additional information). And it's the pattern I see as being the right one, for the immediate future (not going to speculate on what AI might be in five or ten years, so let's just stick with, say, the next couple). We're divorcing the two parts (British and corpus), and using the former with a new wife: "certified" or "trusted" data that we're controlling and managing. So a normal system isn't one that has a LLM and RAG. It's one that uses (one to n, but normally one) LLMs and a series of different RAG pipelines.
Before I go on, I said earlier that this is for the majority of use cases that I've seen, via my capitalist brain, not an academic one. Side note: I got together with some academia types recently, and they're very focused on the linear algebra and things like transformer architectures, and the like. Interesting stuff, if you don't want to eat the sausage without seeing the factory it's made in. Me? I'd prefer to get on with the eatin'.

Anyway, a couple of them were talking about global languages being lost and how LLMs could play a significant role in assuring they're saved. That's a great reason to put the LLM corpus front-and-center. And for things like "write me a poem" or "summarise this article" and "write this javascript...", the LLM in and of itself is more than sufficient. Great use cases. All about the British part, and less so about the data it is returning as the answer. Also not at all the point of this post, which focuses on more diverse and heavy processing, more complexities and flexibility, etc.
Agents, Multimodal, and Services
And that leads us to two more quick (haha) topics, before I get into the technical architecture aspect of this ramble. The first is Agents, which I'm going to explain as separate AI's (again, this is my mental model; technically, it can and usually is a single foundational model). In this model, you can create multiple AIs (if you will; that seems to be the easiest from a mental model standpoint) that act independently, and that includes both the role they play, and the services you give them access to.
So they have access to their own RAG pipelines, if you will. For instance, I could have an AI Agent that plays the role of Customer Support Agent. That AI can only answer questions related to customer support (the realm), and further, only has access to services that a human Customer Support Agent might have, such as a CRM system (which then limits their corpus, and what actions they can perform). You wouldn't think of getting in touch with a Customer Support Agent at your car insurance company and asking them to plan your grocery shopping list, for example. Nor would you give your Customer Service Agent (human or otherwise) access to your financial records. With AI Agents, like with human beings playing roles within an organisation, we limit the Agent to the data (information), the endpoints to interact with that data, and how they can interact with that data based on permissions. AI Agents work very similarly to that. Finally (beyond the scope of this post but worth mention), there are other bonuses around limiting the data that further help with mistakes in how it is used, essentially coming back to decreasing capabilities with too much prompt information in generative AI, but let's just leave that one there as a teaser.
The real holy shit moment for me with Agents was the ability to build LLM applications that have multiple agents, which can converse with each other to accomplish tasks, as discussed in the paper "AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation." Now, I can create an agent whose role/responsibility is to be the Supervisor, and they might not have access to any corpus of information, and have strict instructions not to try. They still have their British side, and they use it to reason about how to answer a question, knowing that other agents have access to different systems. In my earlier example, the Supervisor (or Supervisors; in complex systems, like large companies, middle managers can actually be necessary cogs in the wheel) can take an incoming query, decide it is a customer request, and pass it on to the Customer Support Agent, who in turn can access the CRM it has access to as its corpus, and restrict the data/knowledge to certified/trusted sources. Or perhaps the Supervisor Agent has another subordinate AI that is a Chef, and it has access to a corpus of recipes and nutritional information. An incoming question about grocery shopping might be a query routed to this particular AI, and not the CRM one. But what is interesting is that it's not one-and-done, and it needn't be either/or. Instead, perhaps the query involves both these agents, and now the Supervisor can reach into the CRM system to get a customer's preferences, or maybe their dietary restrictions, and in turn pass that information along to the Chef Agent, which now can make an even more informed decision as to what groceries to buy based on a further-informed corpus of validated/trusted information.
And then the really powerful part is that the Supervisor can get the answer back, which could have come from one agent or multiple agents, and it can further reason as to whether that suffices. If it does, it returns a response or moves on. If not, it continues to iterate, asking more agents, trying again, gathering additional data, and generally acting like you'd expect a human to act if you gave them an open-ended ask. The ability to iterate is so powerful. Reasoning and iterating is even more powerful.
My example here is admittedly a bit of a ridiculous combination, but hopefully it illustrates the concepts. Another common approach is to have an Agent whose responsibility is to examine a response before it is given to the user to assure it doesn't violate any company policies (an Agent in a legal role), and another Agent that assures the response isn't saying anything racist or inflammatory. Now, you've got a set of Agents with access to different resources and services (such as the CRM or the recipe corpus), as well as Agents whose roles are not just Chef and Customer Service, but also Legal, Compliance, and HR. And they're all able to work together in a cooperative manner, unlike humans, who often act, well, like humans.
No More F***ing Chatbots
Honestly, so tired of the AI wave producing "better chatbots." There are so many use cases for AI, and the technical ecosystem around it, that don't have to do with a screen for users to enter text as if it's a glorified Google search. That doesn't mean that the first half dozen generative AI things I built weren't exactly that, but I am thinking about all of it just a bit differently now. Now, I see the power in multi-agent implementations (most Agents in that virtual org chart don't have end-user interaction) and the ability for the AI to reason, and when I open up my own thinking to applications where there isn't a user chatting, some cool shit starts to percolate. And part of that is other services that can be referenced by Agents. Here's an example of what I mean:
Let's say that I am in a minor car accident. My fictitious insurance company has a mobile app that allows me to take a picture of the damage and upload it. That upload of an image might trigger a dynamic pipeline that performs a series of actions, including but not limited to:
Trigger a check to make sure there are no injuries, perhaps with a voice response (which would include both text to voice and voice to text). If I respond that there are injuries, it calls an ambulance on my behalf, and sends the address from the location services of the phone. Simultaneously, it persists this uploaded image to disk, and generates the stub of a case in the CRM system. An AI Agent (the Supervisor) could be dictating the process, and deciding what to do next. So the image arrived via upload, along with the location, and the first thing our Supervisor Agent did was to notice that I hadn't been asked about my injuries, so it ticked that box, and it further understood what to with the response. Maybe my response was that I was okay, but my back hurt a little bit. Not ambulance worthy, but it's not nothing, so the Agent decided to make an appointment for me at a chiropractor, and emailed me a series of open appointments at different offices near my home and work. It also passed the the image that was uploaded to an Agent who did an assessment (reasoning) about the damage, and like the ambulance, figured out where it could order a tow truck from, if applicable, and/or a body shop where repairs could be made, if applicable. Perhaps retrieving an image of the same make and model without damages and image recognition of the damages could lead to an estimated cost. Maybe it also lifted the license from the car that rear ended me, and checked the internal system to determine if they are also customers, and if so, tied the two customer cases together. And that Agent checked with the legal Agent, to made some recommendations about what to say, or importantly in 'Murica, what not to say. And so on. I'm making this up, obviously, and it seems like a bit of a ridiculous app, since much of that needn't be real-time, but hopefully it paints a picture.
I could continue, because there are really so many moving parts to many problems, but hopefully this captures your imagination as to what is possible with this type of configuration, even without ever typing anything into a glorified Google search box or advanced chatbot. In my head, it has the potential to completely turn traditional decision tree implementations on their head, where human-like reasoning can be applied.
And vitally, a bunch of those steps include services that have nothing to do with AI. They're services we've grown accustomed to since the advent of the cloud, and things we build solutions from that don't (directly, at least) include neural networks, or transformer architectures, or look ahead techniques, or one-shot vs multi-shot, or GPT-4 vs Gemini, or any of that stuff. But...all of those services become part of the trusted and certified corpuses that we do want to lean on, and with this model, we can build access to them via function calls (within a function using the likes of boto3 or in isolated Lambda functions themselves). They're all, basically, RAG endpoints, if you will, in terms of returning data/information that it is going to use to augment the response.
I have a point to all of this, and we're almost there.
I've now built out a handful of little multi-agent solutions, and some of them have had text inputs, while others haven't. In fact, I've not-very-secretly gotten really into the intersection of computer vision and generative AI, and that includes using combinations of computer vision services and techniques and vision AI and generative AI. It could mean uploading a PDF and using AI to reason about what it is, and what to do with it. It could include uploading an image, vectorising it to be able to use cosine or euclidean distances to find similar images, and/or using generative AI and vision AI to generate text about that image, and then machine learning, predictive and semantic similarities to find other images. The latter of which I could write another whole post about, but I'll spare the reader more random thoughts, for now. In these cases, I often find myself needing or benefiting from specialised services, like (e.g.) an Optical Character Recognition (OCR) service, or perhaps a text-to-voice service (like in my car accident example). These services become part of the services that AI Agents can access, or they become sources of data that create data that can be fed to the Agents as input.
Learnings and a Repeatable Framework
The remainder of this textual straggle focuses on the architectural patterns shown in the diagram below.
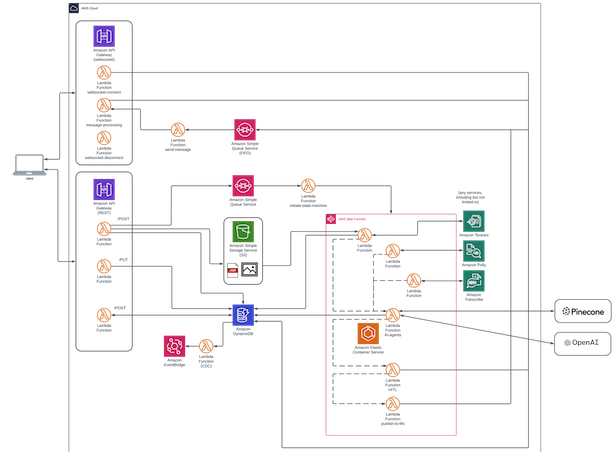
Now, it's worth calling out that using AI Agents (and AI in general) usually includes calls to different services, such as OpenAI for a LLM, or making a call to an embedding endpoint, or accessing a vector database, to name a few. And integrating these more specialised services, such as OCR systems, text-to-voice or voice-to-text (to name a few of hundreds) services, are also intensive, and often, time consuming. Applying Transcribe (AWS's voice-to-text service) takes time to process. When we're thinking about systems that include a UI, those have timeouts (like REST, which is often limited to 29 seconds), and is not something you want hanging that long anyway.
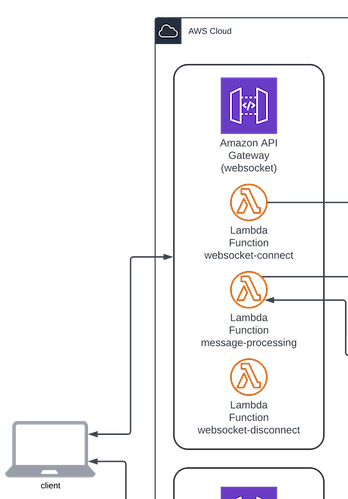
So, I have begun to (by default) just use a websocket for AI based implementations such as those I'm describing here. That way, I can shift things immediately to asynchronous processing, right off the bat, and allow the user experience to not suffer. If I had a query or an image or a PDF (etc.) off to an Agent to reason with, and that reasoning includes making decisions about how to respond or what to do next, it can include selecting services that may require not insignificant processing time. A websocket allows me to take that incoming thing, whatever it is, give a 200 status back indicating it was successfully received, but also tells the UI that it doesn't have to spin until a response is retrieved, because I can't say how long that might be (I don't even know what the execution plan that the Agent might be coming up with, so how the hell would I be able to say how long it's going to take?). And (obviously), the big win is whenever that information is available, the client/UI doesn't have to sit and poll.
Nothing new here: a websocket has certain patterns, in terms of the connect/disconnect/default routes and the Lambdas that sit behind them. I can make those simple and reusable Lambda functions, including the introduction of generic ways to persist and access things like web connection ids, etc. Basically, Lambda functions sitting behind the routes interacting with a DynamoDB table that houses connection information (etc.), and is something easily folded into CDK or Terraform, or your CI/CD application of choice.
Then, when an action is initiated (the image upload or other initiation), the input is passed to a queue (and perhaps to disk, such as S3, which would then mean the bucket and object information is what gets published), the statusCode of 200 means that "yes, we got it", and almost instantaneously, the interface can go on and do other things that don't involve waiting. And, we're now asynchronous. The stuff that happens downstream of that queue happen as they happen, and take as much time as they take. And benefit from reusability and isolation and observability and retries and all the rest of it. And a big part of it is the state machine that is initiated.
A state machine, in the context of cloud orchestration and workflow automation, operates as a model for managing and coordinating the components of a distributed application across a cloud environment. You define a series of states and the transitions between them, which dictate the flow of application execution based on input data and current state conditions. Each state can represent an operation—such as a task execution, a decision point leading to branching paths, or a wait state that pauses the process until a specific condition is met or an event occurs. You can have an Agent as one node within a state machine, for instance, and services either called within that same node, or those services can be nodes in-and-of-themselves. And importantly, a state machine can also include human-in-the-loop (HITL).
Human-in-the-Loop (HITL)
HITL refers to collaboration between the Agents (or the AI) and a human, where the Agents handle certain tasks and efforts, but include a human for sign-off or for validation. In this model, perhaps we've asked the Agents to use various services (perhaps image recognition and machine learning) to (e.g.) identify potential tumours in a patient, another Agent to access the medical records of the customer, which could provide additional insight via family history, etc., and when an alert arises, it accumulates the information and puts it in front of a human doctor before alerting the patient. That's an extreme example, of course, and a simpler one might be a marketing solution, where we've got multiple agents writing copy, reviewing it, and assuring it meets legal requirements and doesn't expose the organisation to litigation. Perhaps we introduce HITL here at an early stage, to sign off on the copy before putting it in front of the Legal Agents, and/or other downstream processing.
I also have additional queue for messaging back to the websocket, or a separate queue if HITL is in the mix and is not the initiator of the state machine. The state machine does become heavily customised, but that's a feature, not a bug. The secret to building big and robust and complex systems is to find little patterns and repeat them over and over. In this case, everything around the state machine is a set of patterns which require very little customisation (but allow for it), and the state machine itself is comprised of more of the same pattern, but those patterns reflect the particular needs of a given system; they don't dictate to the system what is possible.
As I said earlier, I've now applied this exact pattern a few times, to accomplish different things that are in no way related. Problems that involved images and PDFs and text, and multimodal applications, and for different industries and use cases. Much like the serverless patterns that I have long advocated for, and the macroservice patterns I have dedicated far too many words to, to say nothing of patterns in event driven architectures, I'm a huge advocate for identifying patterns and understanding how I can apply them in unique ways to create cool shit. This feels like it's emerging as another one of those.
In the diagram above, I use Pinecone as the vector database (because the serverless offering is mind-boggling inexpensive and the Pinecone service itself is very impressive-I've been converted!) and OpenAI (because it's both the most well known, and I think continues to be best-in-class, for now, at least, though the gap continues to close). Frankly, I think we're kidding ourselves a little if we think the future doesn't include the big kids owning all the underlying infrastructure and controlling the foundation of AI, and I HIGHLY recommend reading this, but I digress.
As always, I stick with AWS, but surely the other cloud providers offer the same opportunity; I just don't use those, so I choose not to speak to them. I'm talking out of my ass enough the way it is. But since I'm mentioning AWS, it is worth mentioning Bedrock, which has the potential to be disruptive, but at this point is a huge disappointment, both in terms of underdelivering, and with hidden costs. Their knowledge base (RAG) defaults ended up costing me hundreds of dollars long after I'd thought I'd removed all of it. I ended up having to get in touch with Support, who in turn also couldn't identify where the services were (they appeared to all be shut down), who then had to hand me off to another group to figure it out, all while I continued to get charged. My month of limited use of that RAG implementation (specifically, the Open Search Serverless Vector Data Store) borders on robbery (they were willing to discuss reimbursement, but by then I was already throwing rocks at squirrels or something angry old men do), and it was definitely annoying as hell. The other thing I struggle with when it comes to AWS is that their analytics services are all trying to abstract everything away, and in the purpose, they minimise what you can do with the underlying technologies dramatically. Glue is a sad excuse for Apache Spark. SageMaker is a sad excuse for decoupled EMR and S3 with some heavy machine learning libraries preloaded. And Bedrock continues that tradition. I get that they're trying to make Data Science, Machine Learning and Artificial Intelligence accessible to everyone, but this approach is not working. If you disagree, explain why the likes of Snowflake and Databricks have the market shares they do. Bedrock could be amazing one day. Today isn't that day. But I digress...

Patterns
Here's a quick run down of the the patterns from the earlier architectural diagram, with placeholders/examples within the State Machine for the purposes of illustration:
The usual suspects are all there: event driven, serverless, cloud-native. I still use single table design DynamoDB instance, I'm still using a Lambda for change-data-capture (CDC) beween DDB and the messaging hub (EventBridge).
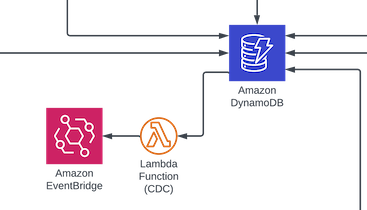
Still decoupling things and assuring that rookie mistakes around things like Lambda throttling are addressed via queues. Not pictured but implied are OAuth (Cognito), CDN and WAF (CloudFront), logging (et al.) (CloudWatch), DLQ and OEDs, blah blah blah.
I still prefer choreography to orchestration, though the state machine obviously introduces a significant amount of the latter. And the reality has never been an either/or, but always a "where best" decision. Because I prefer EDA, I prefer choreography. I've never found the right words to truly convey how I think about those two things, and more realistically, the intersection of them (the interesting piece for me is how to use choreography in order to initiate orchestration, and moreover, how you can leverage outside componentry to disrupt orchestration, like with HITL). And while all of the stuff in the architectural diagram looks incredibly complex, a massive portion of it is repeatable, and insanely simple if you understand cloud architecture. Really, the biggest thing you need to focus on building is the state machine itself, since that's where you get to add the secret sauce that depends on your business, your problem, and your unique offering. But at that point, it's just calls to endpoints and (e.g.) boto3 library integrations, and that's the fun part. But I dare say, even that part isn't difficult.
That's really the point of all of this: generative AI is going to be disruptive (one could argue it already is, but we have to wait for the future in order to be able to connect the dots upon reflection). I don't think the short-to-medium term AI is about chatbots (though we'll continue to be inundated with them) and that type of interaction. More interestingly, I think many people are not seeing the true opportunity because they can't get past what I see as a misuse of the wrong corpus. I think the power is in the LLMs ability to reason and to respond (the British bit), and I see Agents and multi-agent deployments as an incredibly powerful way to access the right corpuses, while intentionally and consciously limiting the access that those Agents have to validated and trusted information. I know, I said all this before, but then I went on a handful of side rants about things, so this is me pulling it all back together.
Stepping through bits of this architecture, for the purposes of explanation: I'm using a websocket in order to both shift things to an asynchronous approach, due to the complexities, flexibility, and time challenges that accompany iterative AI reasoning and processing, as well as to be able to return results without having to poll. In addition to the websocket, traditional REST endpoints perform PUTs, POSTs and GETs as API Gateway endpoints backed by Lambda functions. Nothing especially interesting or new about those patterns or approaches. Just good fits here.
From there, a Lambda subscriber to that queue initiates a step function, and then exits. The step function itself is where you'd introduce differences from one deployment to another. Sticking with the car insurance example to here, a product that is triggered with a picture being taken from our app...actually, wait. This has to be the first post ever that chooses to use car insurance while still trying to keep the readers interest. Surely some insurance company somewhere has a Solutions Architect or technical strategy type position writing internal shit like this. But nobody chooses to use car insurance examples. Anyway. As I was saying, sticking with the car insurance example to here (!), the product that is triggered with a picture being taken via the app, which in turn is not only triggering various workflows depending on the fact that a session has started, and is also employing AI Agents to "reason" about what steps to take next, along with the concept of iterating over the results of that...and for that to non-determinist, is interesting.
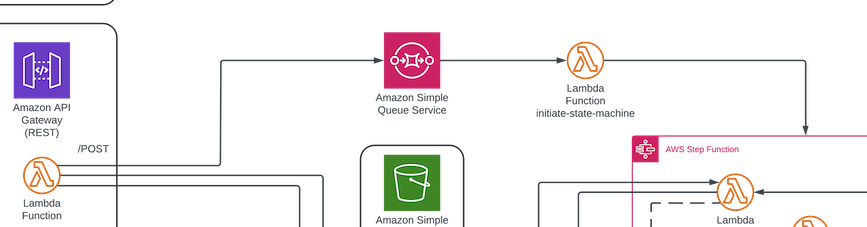
So while the step function has whatever flexibility you want to introduce, the way I'm using it (and how I think this works best, with my few data points) is that I normally think of step functions as playing the role that scheduling tools; with functionalities relying on directed acyclic graphs (you can't call them DAGs in New Zealand. Learned that one the hard way more than once) as job A runs and then jobs B and C run after that, and after C, there's a distinct pipeline, and a different one from B. And sometimes things from multiple branches have to all happen before things can proceed, as shown in my stolen Wikipedia image:
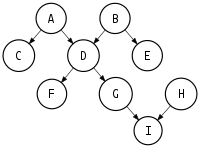
And at the end of it all, you get a big green light that means the nightly ETL is done (for those of you who get that reference and it gives you pain in your chest, you are my brothers and sisters).
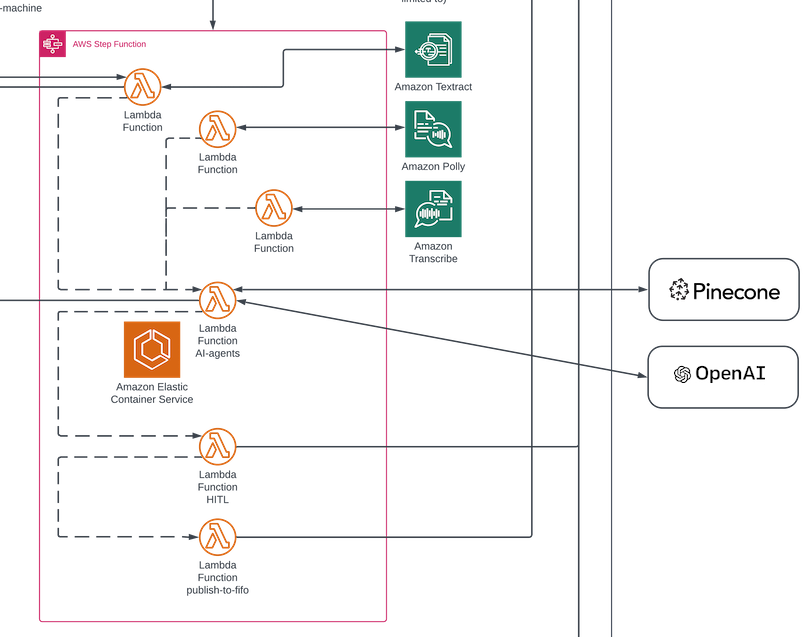
In this case, first off, it's a miniature version of dependencies, but I use the nodes not as the same kind of steps, necessarily. Instead, I find myself introducing multiple things that can happen depending on what the input data is as a bit of a pre-processing layer. For instance, if the payload that the Lambda function that reads from SQS and initiates the step function contains references to, perhaps, S3 objects, depending on their type, I might need to:
- Vectorise and write it to a vector database Read an object from S3 and perform OCR against it (using this because I referenced it earlier)
- Read an object from S3 and perform text-to-voice against it (using this because I referenced it earlier) Read an object from S3 and perform voice-to-text against it (using this because I referenced it earlier)
- Consume text data from a DynamoDB subscriber to Eventbridge Consume form data from a RESTful PUT or POST call from the client
- etc.
In and of itself, that's pretty normal, but in this case it's so that I can create specialised jobs that do a thing, as opposed to building some sort of uber-thing, that tries to all the jobs but ultimately ends up being a beast to extend or maintain, but at least it is vital and everything falls over if it breaks (hopefully the sarcasm is noted). In this instance, the individual processes limit the blast radiuses and can work independently and in parallel, and importantly, it's updating the corpuses of endpoints, and outputs are creating input context for the Agents to consume.
Again, whatever those things were, I consider them the necessary pre-processing so that the Agents have access to the data they need, whether that is the text lifted from a PDF, or the form data being validated and persisted. Just because this is a step preparing data for AI usage, that doesn't exclude it from using AI to accomplish that, though I find that is a bit less common. However, if I wanted to do some pre-processing using vision based AI (side note: I've been very impressed with GPT-4V for a bit of time, and it's gone generally available now), I would do that in this pre-processing layer. And because of that and of other pre-processing that rely on AI libraries and the dependencies thereof, I use a Docker container here, with Elastic Container Registry (ECR).

In my experience, especially with Lambda and ML or AI libraries, by the time you've fucked around enough with custom libraries and layers and certified layers, and zip files to S3, and EC2 instances where you can install Linux because the differences between it and what you get from a Mac and C++ compiled vs other...if you're a Python dev who even has to screw around with numpy in the cloud, you surely have some level of PTSD from this type of experience), you might as well have just created a virtual environment and a Docker container (despite my disdain for having to manage containers) and been done with it. Now, I start there if AI libraries are involved.
So where AI is used, a container is often a must-have (for sanity reasons), but generally I think of that layer as the pre-processing so that the Agents have up to date information (corpuses), and our Supervisor now has all of the information it needs (inputs) in order to make decisions as to what to do with it.
That node has the Agents and it's using maybe using langchain or langgraph or hugging face or openai sckit or tensor, or what-have-you. It's probably accessing the vector database, or endpoints that it got via a Swagger doc (that's a brilliant approach, by the way, which assures it isn't mine. A comprehensive Swagger doc as prompt context you feed to an Agent gives it all the information it needs to perform a lot of tasks, but let's get back to the point here, assuming I have one), or perhaps an internal RDBMS, or even just a custom Python library containing a centralised set of internal and reusable functions or 3rd party RESTful endpoints. So this one has heavy libraries, and it needs to run for sometimes a few minutes. It's still a Lambda function, but it is one that runs a bit longer, and is also a Docker container (ECR).
For the HITL, AWS step functions have a task state with waitforTaskToken, in which continuing the graph depends on an external (in my case, Lambda) function passing back the task token via a sendTaskSuccess API call. Out of the box, an AWS step function can execute for something like 364 days, so there's a lot of interesting stuff you can do just by having the ability to pause and wait and restart a state machine, but that's another conversation for another day.
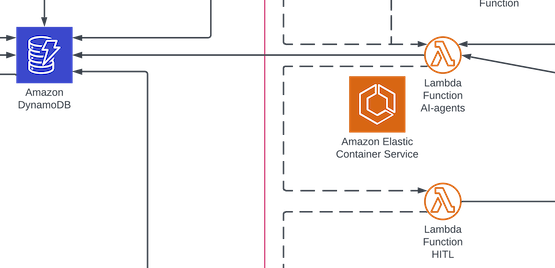
From there, any additional processing can happen, or maybe some reprocessing needs to be done, etc. Whatever the human says goes. It's like being married. At the end of it all, and potentially at various points from within, I publish to a FIFO queue, which in turn writes the message back to the web socket. So throughout this whole thing, from within a Lambda or as a node in the step function, I can publish anything I want back and it will show up on the client essentially as if it were a request/response from a normal REST, but with the introduction of a flexible and robust set of AI functionalities.
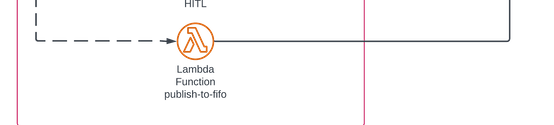
I can now deploy this framework in a matter of hours, and focus on building the cool shit. It's just another little pattern that done over and over again is how big and intertesting things get done...
Thanks for reading.



