
Setting: I have in hand a pint of Garage Project's January Fresh, and I'm thinking about some architectural concepts and approaches as key components to achieving true speed and agility for practically any size organisation, with any level of tech debt, including if the underlying components of your technology stack don't follow the same architectural patterns. Moreover, I'll argue that it even helps employee retention, and enables multi-cloud implementations. Grab yourself a pint (or something stronger) and join me as we take a voyage into my brain (yikes).
Organisational Goals Dreams
You've probably had someone say to you, or you've said to others (shame!), something along the lines of "it doesn't seem like it should be this hard" or "it doesn't seem like it should have to take this long" when discussing a tech project. Sometimes, it's said because the person is a wanker (because I was born and raised in America, this word entered my vocabulary far too late), but most often it's said because, well, it shouldn't be this hard, or take this long.
Why Me?
I believe in the pursuit of perfection in the things I devote the largest swaths of my time and attention to. As a technology professional, that manifests itself in part as a journey to find the perfect collision between speed and the ideal outcome in delivering technology products, recognising the thousands of (shifting) factors that go into it. I'm sharing some of those learnings here. They're all subject to change as I change. Honestly, we're all just practising in public.
|
“Actually, I wanted to play for anybody. I could never sit in a room and just play all by myself. I needed to play for people and all the time. You can say I practiced in public and my whole life was becoming what I practiced.1” -Bob Dylan |
I continue to search for the best technologies, patterns, architectures, concepts, techniques and practices (specifically the concepts and patterns), and vitally, the collisions between all of them in order to build the best technology solutions the fastest, like searching for a moving point in a multi-dimensional graph.
I'm going to talk in this post about the Event Driven Architecture, or EDA, and how the concepts behind it can be applied at different levels of technology within your organisation to achieve various desirable outcomes.
These outcomes range from alternatives to paying back technical debt, to getting your startup groove back (or creating one for the first time, if you're a more mature organisation) by creating speed, how it is the best way to achieve cloud independence, and how it can help you create a high performing organisation. Yeah, pretty lofty goals, but whatevs. Aim high-n-shit.
Here's why we can pretend I'm qualified to write this post: I've been working in and around event driven architectures since about 2015, after working in technology since the mid-to-late 1990s. I know it was 2015 because AWS launched Lambda functions the previous November, and that was a really big unlock for me. It was the start of my (ongoing) love affair with serverless, and by that time I'd already been working in AWS for about 5 years, so I had a pretty good grasp on the AWS cloud thanks to some great colleagues over those years. At that stage, I'd been focused on designing and building out big data/analytics/data science environments that could be truly and fully elastic (meaning: bi-directional scalability, doing so seamlessly in each direction, and the ability to scale from zero out "infinitely"). What was scaling in that architecture were clusters of servers for compute with decoupled infinitely scalable storage. I've written extensively about this in the past (none of which is necessarily worth reading), but I emphasise it here because it's the same pattern that is repeated with Lambda (Azure and GCP offer their own Functions services...same idea) and the serverless execution model. I say Lambda specifically because (I ♥ AWS, and...) I want to avoid managing containers, if that's possible, for the most basic of reasons: it's one less thing that can go wrong. Never forget: all code is a liability, because all code can, and does, break.
|
Everything fails, all the time.
-Werner Vogels |
More Why Me…Me. Me. Me.
Back in the golden olden days of the 2010s, I was building out and helping companies adopt horizontally scalable ephemeral "big data" analytics and data science environments. At a high level, we were taking clusters of servers (themselves horizontally scalable, since you could dynamically add or remove servers, or nodes, from those clusters as needed) and viewing a cluster as an individual "unit", regardless of whether a unit contained two servers or two hundred of them (that is itself very useful, and it's also the reason that on-premise clusters are not actually dynamically sizeable or inherently elastic or truly horizontally scalable, unless you have a closet with thousands of unused servers lying around, in which case you would be a fool. The cloud is the difference maker, of course, because they are the proverbial closet, but I digress).
The same patterns I was applying to a completely ephemeral, horizontally scalable compute environments (scalable at both an individual cluster level and as the number of clusters) with decoupled persistence storage, we can see elsewhere.
The concepts of building systems that can scale out to process terabytes and petabytes of data for (e.g.) training predictive models, through the use of dynamic numbers of clusters of servers are the same patterns that apply to building out individual functions that process a few thousand bytes of code and live little mayfly-esque lives (female mayflies usually live less than five minutes, while males can live a whopping two days, per the intergoogles), except that instead of minutes or days, we're talking about seconds, so Function-as-a-Service (FaaS) has always resonated with me, too. And yes, that is probably the last mayfly comparison I make tonight.

So, a younger (and freakishly handsome, at least as I remember it) me is building applications and frameworks, including in a quick read-it-twice: the very framework to build and deploy ephemeral distributed compute environments, via a multi-EMR and decoupled disk (S3) plus a centralised external hive metastore level, was built using ephemeral distributed compute (at a Lambda level)...and Event Driven Architectures are a natural approach to doing so.
I was using events (things like requests for compute, notifications of completion of processing, events indicating if a cluster needed provisioning, event checks of whether a cluster has spare capacity, messages indicating additional clusters are needed, whether to scale those, and when to terminate, to name a few different event types) and FaaS (Lambdas that trigger to do stuff that the events are indicating), and I started to more deeply understand the paradigm, and more importantly, gain career capital in deploying it. That part is really important because it shifts things from an academic or theoretical discussion to one that is grounded in reality. AWS being AWS (amongst others) probably saw many of the same opportunities I did, and they and others started to create services and offerings automating many of the concepts. The likes of serverless EMR, the Glue metastore (I won't comment on the disappointment that is the wider Glue service, but I’ve got a rant), Snowflake, and a bunch of Apache frameworks are good examples, as is Redshift's Spectrum, to throw some top-of-mind ideas out there, from a pool of many.
Semantics & Definitions Alignment, for the Sake of this Post
To be clear, EDA is an architecture. Serverless is an execution model. FaaS is a category of cloud computing. I'll call it a pattern, and if you're cringing at that categorisation, or any of the others...oh well. It's also not really important to this discussion, and if you've ever been subjected to my random bullshit posts in the past, you should be accustomed to cringing.

What I'm going to talk about today is EDA at the highest level of your technology strategy and why I think it's so important, including what benefits it can provide. This is about why I like that technical architecture at the macro/overall architecture company level, and the areas to focus on so that it doesn't go wrong. For folks reading this who feel chest pain at the mere mention of yet another technology migration or purchase, this won’t kill you because this is not that.
This also isn't a post that is going to explain EDA better than the bajillion other sources on the interwebs. I'll leave that to your own research. And if you've got a complete greenfield opportunity, and are starting with EDA, you're probably applying (or considering applying) it within that budding technology environment (those truly greenfield are the most fun, and the hardest to find, you small minority of lucky humans), then maybe this post gives you something to consider you hadn't before. If you have an existing technology stack, or stacks, and no architectural strategy, or multiple of them, etc., then CONGRATULATIONS! you are part of an exclusive club called "Everyone Else." And that club might still want to leverage EDA on their (e.g.) new app or web site, or internal-project-to-make-things-better. And finally, if you've got a number of different architectural approaches or combinations of legacy code (and by "legacy" I simply mean: "code that we would rather not add to or touch again") and new development that you do want to continue to extend on sins of the past (damn you, sunk cost fallacy, you won't get us again), then you're an intended audience member, too. Hopefully, it doesn't disappoint.
EDAs fundamentally centre around the asynchronous transmission of events that encourage and enable decoupling. That decoupling can be between a front end and a back end, between two different processes in a single project, or at a higher level, it can decouple entire disparate systems. Let's quickly cover a few of those just so we're all talking apples here.

We could have a simple webpage with a form in which a user clicks submit. Clicking submit sends a message containing the form information to a multi-subscriber messaging hub, and then anything that cares about the information in that form (perhaps, say, directly related systems like capturing the account details in the customer modules, the module that processes the order, and payment processor) essentially "wakes up" and does whatever functionality it needs to do.
At an enterprise level, perhaps other otherwise independent systems care about it because they retrieve the product from a warehouse, while a completely different system reserves space on a truck for it to be shipped, while our analytics team wants this information so it can be included in dashboards, and our data science team wants to leverage it so they can build a prediction for this customer to buy something related to that item! Remember, all of these systems were built at different times over the years, using different technologies and different approaches. Each one is like a child in a large family. Each came out at a different time, and while they all have some of the same DNA, they're all unique, and sometimes wildly unique. Huh...I love that analogy, and it coincides with needing another pint while I think about the trademark. I’ll be right back.
Quick sidenote: find the time to watch this fantastic keynote on asynchronous events.
In each of these examples, a bunch of processes were initiated by a single event: the user filling in and submitting a web form, so that's one way to think about the event portion of it. And anything can be an event. A form being submitted. A photo being uploaded. A node.js script executing. A particular time of day arriving. A piece of infrastructure failing. A patient being admitted. A butterfly flapping its wings in Brazil. Okay, the last one is an Edward Lorenz reference, but you get the point.
From a decoupling perspective, if any of the subscribers (or consuming systems) were down for any reason, the overall ecosystem doesn't fall over. In fact, those events just queue up waiting for the system to come back online, and then the consuming system performs processing against the backlog. Imagine the shit-show if your data warehouse system (for instance) were to be doing some sort of big software deployment, or maybe a tornado knocked out power to their data centre, and was offline for some period of time and none of the other stuff in your pipeline were to work! Imagine how ridiculous it would be if your building losing power caused customers not to be able to order products. That's hand-wavey and extreme for illustration (if nothing else, the building’s technology system should have been multi-region to start with and had automatic failover in place), but systems go down all the time (intentionally and unintentionally), and when they do, you have to have overall resilience to accommodate those unknowns. EDAs, properly done (various aspects of which will eventually be discussed if I ever get there), provide that safety because they are fundamentally decoupled.
Thinking about Technical Strategy in Tiers
- Highest tier: the overall approach that ties everything together. This is the layer in which you see all the system and solution parts, whether they're connected or not. This is your website, both of your mobile apps, all the stuff you've built in the cloud, your data environment, your HR system, your CRM, and hundreds of internal projects and integrations with 3rd parties created over the years, and the hundreds more you'd love to do. If you were drawing it on a piece of paper, with circles for each of those systems, that would be this tier
- Middle tier: these are bounded contexts. I'll loosely define this "any work initiative that has a kickoff meeting", which could range from an internal project that (e.g.) manages meeting room availability, or a customer support AI project, or an entire mobile app, or a new website, etc. These can be subsystems that integrate together to create the circles in the highest tier, or maybe they are those systems
- Low tier: the patterns discussed at the individual service level, and the roles of each therein and why, because...nerd
Getting Your Startup Groove Back, or Building One for the First Time
Everyone knows the stories about the likes of Steve Jobs and Steve Wozniak building Apple in their garage, Bill Gates and Paul Allen doing the similar with Microsoft, Jeff Bezos and former wife MacKenzie [Scott] driving to Seattle and starting Amazon using old doors on saw horses as desks, and Brian Chesky and his friends doing similar with AirBnb. The history books are littered with examples of small groups building amazing things over a small handful of months, and here you are, overseeing or a part of a team that can't seem to build a "Hello, World" app without ten people sharing their opinions about whether or not you should use epoch timestamps or more human readable ones. And the response is sprints and burn charts and more resourcing and more meetings and more discussion and more bullshit; none of which actually speeds anything up, and all of which makes the devs who haven't fallen to the dark side rethink their life choices.
For you, the reader who sees the irony in embracing a methodology that began from a desire to remove unnecessary processes and bureaucracy that now has printed materials outlining those processes and classes to get the certifications to prove it...trust your instincts...unfortunately, I can't help you with that. I'm pretty sure that Steve and Woz talked about things they were working on and made sure that they were communicating roadblocks, but I doubt they spent 15 minutes sitting around a table (while calling it a "standup") every day to do so, and I’m absolutely convinced they didn’t have any ridiculously stupid burn charts.

If you've ever been in a startup, you may have experienced speed, like that of these legendary tech garage bands. You remember fondly "back when I started here, we used to move fast."
Take it from an old person: you sound like an old person.
To be clear: all startups are not fast. They can suffer from all kinds of speed killers. It’s just that most of them that lack speed run out of money before they accomplish anything, so you don’t hear much about them.
In my extensive experience (see: old person), the primary killers of speed in startups are (a) indecisive leadership-and I think this is the biggest offender. There is little I have less patience for than leadership that can't make a decision or that believes everything is democracy. It's not. Want to move fast? Make some calls, even if they're unpopular. Disagree and commit. Go. (b) Well intentioned outside forces that have too much influence on what is worked on without enough technology expertise to understand the ramifications of that influence, or (c) you aren't actually a startup anymore, even though you cling to that moniker because you know the alternative isn't as fun or exciting. Worth noting: moving from startup to scale-up (and beyond) has its good parts, too. But generally, everyone starts to notice speed deteriorating.
What I want to do is explore the issues we have in becoming slow as a systemic issue. Further, I want to explore what all those small, successful teams that build huge successes did to be fast, and what we can do to replicate that. Don't get me wrong, I understand that two individuals in a garage can quickly develop a tech product due to their agility, minimal bureaucracy, and singular focus, whereas large corporations face complex processes, diverse stakeholder interests, and extensive approval procedures that can significantly prolong even simple updates, and a post that some dipshit (me) writes that probably nobody will ever read isn't going to address all of that, but what I can do is talk about how we can create some of the same startup characteristics in our companies of any size and achieve relevant speed. Maybe I can't make you the fastest, but I can make you faster.
On the other end of the spectrum, perhaps you're part of an established, mature organisation. Perhaps you have hundreds or thousands or tens of thousands of developers, and it is all the more frustrating because those startups don't have the same financial resources to hire or pay talent like your company does. And as much as the solution too often feels like you need to add more hires, at your core you should learn that that is rarely the right answer to actually achieving speed, which is mostly because of Metcalfe's Law ("The influence of a telecommunications network is proportional to the square of the number of connected users of the system (n2)") and Brooks Law ("adding manpower to a late software project makes it later"4).
When you hire, it's usually because your team has too much work to do, but the reality is that a lot of the work you are doing is work that wouldn't be done in a startup at all, and if we could get beyond our own trees to see the forest again, much of it needn't be done in your organisation, either. I think what I’m talking about here helps in this regard because you end up hiring less supporting cast, and overall, less developers, too.
Getting back on point, mature organisations have lots of processes. They have made substantial investments in existing technologies, coupled with organisational structures and processes optimised for the status quo, and that can create resistance to change. Additionally, beyond-startup-sized-organisations are supporting existing revenue streams.
Think about it this way: for a more established organisation, you have technology assets that are already generating revenue (that's why they've grown beyond being a startup, after all), so there are increased risks in touching that code. Getting it wrong could mean turning away existing customers, or impacting existing revenue streams. And how do companies trick themselves into thinking that they're protecting those revenue streams? They add additional checks and balances in the form of more processes and bureaucracy, and they hire more devs to support the old and build the new, and they add a shit-ton (a very scientific measurement) of supporting people to do the same, in the form of testers, project managers, product owners, delivery managers, etc. In an effort to protect the existing technology assets, they do all kinds of things that shift the organisation away from the characteristics of the garage band. It all happens from the right place, and it all makes logical sense, and it all results in things that move us away from creating environments that help us to move fast.
The strategies and actions that previously led to our current success are now the very practices we're consciously avoiding in order to safeguard and build upon these achievements.
I heard Adrian Cockcroft say that once, and it has always stuck with me because he's right (he almost always is, by the way).
So we're trying to take some of the lessons from the tech garage bands, and the lessons from startups that actually move fast. We understand that everything is subservient to speed, and that speed is relative. What is fast to Woz is not going to be the same thing if we put him into Apple forty years later, but we can also understand that Apple has continued to be fast, when compared to...well, practically all other companies, and certainly companies of their size. To be crystal clear: when I parrot Adrian with "everything is subservient to speed", I'm talking about "the fastest we can deliver with the right level of discipline." I'm not saying we focus on speed and disregard security, or throw shit code against the wall and hope it sticks. I'm simply saying that you are slower than you could be, and I have some ideas for getting your groove back that don't include fixing (or getting rid of) leadership that are too worried about their popularity and not worried enough about their real responsibilities of creating a profitable company, or convincing your company to throw away Scrum (they should) or creating a better approach to talent acquisition (they really should). I'll get there, after a note about how this can help on the talent front, too, sans fixing that more deliberately, but the point so far is that we'll gain speed by re-creating characteristics that are commonly found in startups and tech garage bands.
Tech Debt
One more thing that can derail the best intentions, and that's around tech debt. If you are sitting there reading this (get a life!) you would be forgiven for saying that this is all good and fine, but the startups don't have tech debt, so it's easy for them to focus on writing new code.
You, however, have years of sins of other devs to deal with. You have to manage paying it back and you have to worry about integrating new stuff while working around the buried bodies. You don't have the luxury of starting with a clean whiteboard.
You have to take whatever deck has been dealt to you - most of it tech you would have done differently in the first place, and make it work. And make it scale. And make it robust. And make it more resilient. Nothing about your situation and a startup seem the same.
I argue the approach should be.

This part of the discussion is directed towards organisations with legacy code. Again, when I say "legacy" I mean something like "code I don't want to continue to extend." "Legacy" needn't carry a negative connotation so much as a recognition for work that was done in the past. It could have been last week or last decade. Some legacy code, like COBOL at a bank, is old and folks are scared to touch it because if something goes wrong, heads are going to roll and people's money could be at risk. Other times, it's code that is working, but it relies on outdated frameworks or languages that the company has moved on from. Still other times, it follows frameworks that have become dated because technology doesn't stand still. So maybe you have a bunch of .NET code and you're tired of the Microsoft stack, or maybe you're shifting from GCP to AWS, or you still have some archaic LAMP architecture and a couple of PHP tech grandpas who are clinging to it like a child clings to their security blanket, but the rest of the firm is ready to move into this millennium.

Full disclosure: I have a couple of old PHP colleagues who get really pissed off when I hack PHP, which only makes me do it more. You know who you are, and deep down, you know I’m right.
|
Joke of the Day I saw an ad for a PHP developer at Pornhub the other day. It was really attractive, but I don't know if I could bring myself to admit to my friends and family that I do PHP. |
Or maybe you, like everyone else, have tech debt. Well, I'm going to say the quiet part out loud: tech debt simply very rarely gets repaid, and never gets fully repaid, and you should stop lying to yourselves if you're saying otherwise. To be fair, all things labelled as tech debt are not actually tech debt. Most companies around today that have years of history also have years worth of varying technology solutions, based on when they were built, and for what purposes. Those solutions will vary in technical terms because of:
- What infrastructure they were built on
- Who wrote them
- What languages and frameworks the software was written in
- What architectural patterns (if any) were followed
- A bunch of other stuff (including but not limited to varying approaches to CI/CD, what monitoring tools they use, etc.)
It's not you, because you, dear reader, are perfect and completely flawless, no doubt. But regular humans aren't, and regular humans who do tech stuff have a tendency to come into any new project, or existing code base, and instead of saying "hello" they say "who is the dumb ass who built it like this? They're dumb stupid faced stupid heads."
And if that person has clout or glimpses of a point, or barks loudest, or even if you just get bored arguing with them, eventually the existing code base gets labelled "tech debt", even if it's actually just a different opinion, or maybe there were extenuating circumstances, like unrealistic timelines or organisational factors that aren't remembered or visible by looking at if/then statements.
The devs and those close to the project at the original time of the build are the only ones who know where the bodies are buried, and devs have short memories and shorter tenures. To make matters worse, even new projects accumulate technical debt, for the same types of reasons. Tech debt is both a real thing that is desirable to avoid, and a label that gets applied to existing solutions because some yahoo would have done it differently or doesn't know the circumstances at the time of the build, and has chosen that code base as a starting line from which to launch a pissing contest. Make me a picture, Dall-E…

I think the exceptions to the statement that tech debt never gets paid back are the two following criteria:
(1) the code base is going to be under construction for an unrelated reason (e.g., because it is being extended to add other functionality and therefore updating it necessary to make the new parts work)
-or-
(2) it's broken
Under (2), the issue is more often than not that there is a bug, but sometimes it's a performance issue.
And I'll argue that if it's broken, it's not really tech debt. It's just broken. But the bottom line is: it's (almost) never repaid because repaying technical debt is not the optimal way to spend the most finite of things: time. You will always have something more important to work on than repaying technical debt that isn't going to provide additional benefit that outweighs the potential benefit of doing something else. Code that is shipped is shipped. It's out there, baby.

Again, as someone who has, with the most genuine intentions, created and promised to pay back tech debt, I know that's hard to accept, because every time you chose to cut a corner under the guise of we'll fix it later you actually meant it, and because with every single initiative some level of technical debt exists. But if the code is correct enough, and performs just well enough, and that project (or more specifically that part of the project) isn't under ongoing construction, the code labelled as tech debt is just code.
Adding to that, even on new initiatives, unless there is infinite time and money, some corners are going to be cut. You have to get to done. Things like "perfect is the enemy of good enough" get said. You have to launch the product, or move on to the next initiative, or fix something else. And even if you had all the time and money and no other work to do and you delivered what you think is the perfect output, that yahoo from earlier is going to come along someday and call you a dumb stupid faced stupid head, and working code will be labelled technical debt. And it won’t get repaid. Sigh.
But since it's delivered, it now qualifies as something other than (minimally, in addition to) tech debt. It's code. It's a solution. It's an application or a delivered product. It saves someone time, or it generates revenue. It's technology that your organisation is using.
Once we set free anything-that-someone-doesn't-like from the "tech debt" moniker and view it simply as a technology asset, it gets the same rights as any/all other technology assets within the organisation. Now, it becomes a piece to the larger puzzle that is your overall technology architecture. And in doing so, it becomes part of a larger technology strategy. And it fits together based on the data that is shared from and to it.
I am giving all of this information because it enables us to leave our existing technical assets alone, which is huge. It's very normal for your existing company to have had a number of technology experts and developers and architects come and go through the years, each bringing their own opinions and specialties. And to their credit, technology has changed over the years, and they've changed, too. It's incredibly normal to have some combination of monoliths, SOA architectures, microservices, n-tier architectures, request/response systems, batch processing, etc. It's also common to see LAMP, MEAN/MERN, Ruby on Rails and a bunch of Java in different areas across the company. And all of this resides alongside their own tech debt (or technical assets labelled as such).
What I am saying is that none of it needs to be touched in order to adopt this strategic approach. Instead, the idea is that you leave everything alone until one of these systems needs to integrate with something else. And that something else could be new development, or maybe it's a recognition that combining multiple existing systems creates new revenue streams, process improvements, cost savings, or other driving factors in creating new code. And when that happens, you should first and foremost think about combining those systems via the sharing of data. And moreover (and vitally) when the system needs to integrate with something else that the sharing of data happens through the right EDA concepts and patterns; in this case, that's queues (or similar that perform the same type of decoupling and resilience). I'm going to speak here in AWS terms (because see earlier comments). This means that SQS becomes the service and technological approach of sharing data (and in doing so, integrating disparate systems) in a decoupled manner. Let's explore with an example.
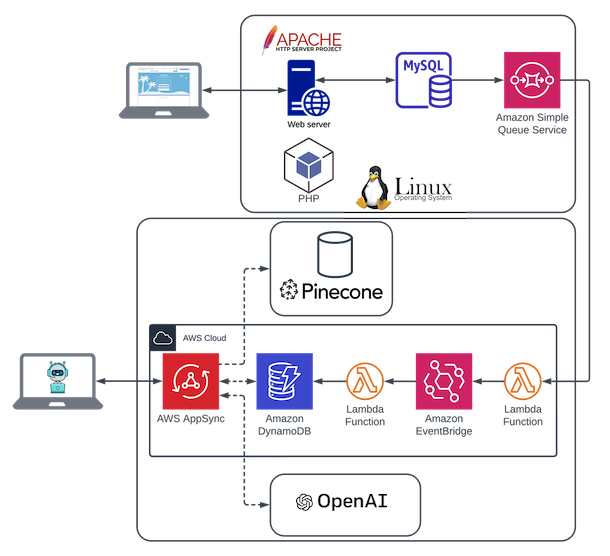
Let's imagine that we have an existing on-premise LAMP architecture that manages a website. That website makes travel plans (it could be anything). A customer can log on to create hotel/airline/cruise reservations. Those reservations are captured in a MySQL database. This system was built fifteen years ago, and despite it being old, it works. By our definition, it's not technical debt. It's just another technical asset.
Now, we're introducing a new initiative, which is an advanced chatbot, leveraging generative AI. That system is going to be fine tuned on internal data, which we're going to store in a Pinecone vector database. It's also going to leverage OpenAI to generate responses to the customer, which is going to leverage the documents stored in the vector database. This initiative is going to be built in AWS, and it's going to tap into some more modern technologies, including NoSQL (DynamoDB) and GraphQL (via AppSync). It also has to have access to the reservation data originating in the LAMP architecture, but going in and changing the MySQL database, which is an ODS by design and should remain as such, is not ideal.
Moreover, I argue that it would tightly couple these two disparate systems, and that's the kiss of death. That is going to create dependencies between the two, and increase risks, because now we have to touch the legacy system, which (if not for this chatbot initiative) would be able to remain completely separate. Instead, we should add a simple data sharing from the MySQL database to the chatbot architecture, either via mini-batch (if need be) or a Change-Data-Capture (CDC) approach, simply publishing the relevant information to a (SQS, in this diagram) queue and working under a fire-and-forget approach. There is no reason to further touch the existing website, and we're actually mitigating risk by allowing it to run as it always has, and to be managed the same. In this case, the only thing that has to occur is a CDC (or similar) process that publishes the data to a queue, and the processing to assure it works.
| [A] loosely coupled design system has few interdependencies between the component parts. They are designed so that each can be adapted without going back and changing the foundation. That’s why software engineers like loose coupling; they can make a change to part of the system with no repercussions for the rest of it. The entire system is more flexible.2 |
Obviously, combining different technology solutions to create more robust offerings makes the whole stronger than the sum of the parts. It creates more flexibility that enables more creative solutions to be developed. Unfortunately, while this is all logical, in practice this idea doesn't usually deliver on the promise, because integrating disparate systems, and systems that were developed over long periods of time, and developed using different architectural approaches, using different languages and frameworks and infrastructure is really freakin' hard. And because those existing systems have lots of buried bodies, it's even harder. It's no wonder tech is slow and expensive. We're paying for our past sins, for the sins of others pasts, we're trying to keep up with a constantly changing ground beneath our feet, we're getting beaten up from above by folks who say shit like "it shouldn't be that hard", and we're going as fast as we can while juggling the technology world around us. And techies aren't exactly known for their social skills or patience. A fine looking crew, however.
The key to breaking the cycle is enterprise event driven architectures, because they are asynchronous by design. Because that approach enables decoupling. The ultimate goal is decoupling.
Why is the Ultimate Goal Decoupling?
Because it allows legacy code and new code to (a) reside together and (b) be built/extended at pace, using the right tools for the job. From a technology standpoint, this is what you have to focus on to be effective and to be able to leverage technology as a true differentiating factor in the business. The alternatives (either trying to fit square pegs into round holes by making everything adhere to a single approach or extending monoliths - see the challenges in the banking industry that make disruptive change hard - and never accomplishing anything) are worse.
Revisiting the Tiers
At the top tier of the architecture, then, is to apply the concepts at the strategic enterprise level to leverage EDA across the entire technology stack, as a whole, as the means by which to integrate between any two systems, and to do that via asynchronous events. It doesn't actually matter if any of the underlying project architectures are EDA; the overall architecture still can be, and it will create a plethora of opportunities. It will, in and of itself, create speed because it means you don't have to retrofit anything. If it needs to share, send events to a queue. The only exception here is where true request/response is needed, which is the rare exception, and can be dealt with in any number of well-documented ways.
Emphasising the point: the key to success, at the top tier, is the connections. It is about being disciplined in enforcing queues (or other technologies that accomplish the same) as a means by which to both share data between disparate systems. This allows you to leave your existing technology assets alone. It enables you to not have to migrate to a single/shared technical architecture, or a single hosting platform. P.S. This works across organisations, too.
What Does This Have to do With Speed?
Simple: we established that speed's tech enemy is dependencies. EDA eliminates dependencies via decoupling. With this approach, we're enabling each of the individual teams to focus solely and wholly on the effort directly in front of them. (e.g.) The two people who are working on the generative AI project earlier don't have to coordinate with the ten that manage the website. We don't need meetings that include all twelve (nor do we need the PMs and others that accompany them), which means we avoid the time lost to Metcalfe's Law, and we recreate the environment of the tech garage band.
You want to create boundaries within which you can build independent system components (of any size) with the minimum number of people necessary to do so. And the number of people you need is closer to two (see: Apple) than it is likely what you've got going at the moment. Small numbers of 'A' level talent accomplish exponentially more than large groups, full stop, and large groups suffer from a natural regression to the lowest level of talent. That's not an opinion, it's reality.
The middle tier are those bounded contexts. A bounded context, in this discussion, is a project. It is the website using a LAMP architecture and it is the generative AI project used in examples earlier. Or a mobile app. Or the introduction of a CRM. Or a new data science initiative. If the top tier is the connections between things, the middle tier are the things. The things are bounded contexts.
I think this is the right time to talk a bit about macroservices/mini-monoliths (I'll use the terms interchangeably), because that is really what I'm promoting here. In my experience, with microservices we risk creating services that are too fine-grained, leading to an explosion of services which are, in turn, hard to manage and maintain. This granularity can result in excessive communication overhead, as services need to frequently communicate over the network, and worse, it can also make the system as a whole harder to understand and debug. I also think, practically, that it leads to a need for more developers, especially if the company understands the impact of organisational structures on technology (see the short Conway’s Law discussion later).
My preference is macroservices, or mini-monoliths, which provide a compelling solution to the challenges posed by overly fine-grained microservices by striking a balance between the monolithic and microservice architectures. By grouping related functionalities into larger services, macroservices reduce the proliferation of excessively small services, thereby mitigating the complexity and management challenges associated with handling numerous independent services. This approach lowers communication overhead, as there are fewer service-to-service interactions over the network, leading to improved performance and reduced latency. And, by consolidating related functionalities, macroservices simplify the system's architecture, making it easier to understand, debug, and maintain.
In my experience, macroservices offer a more manageable and efficient architectural choice, providing the benefits of modularity and scalability without the extreme fragmentation and complexity that can accompany a microservices approach.
And importantly, your existing technical assets can be viewed as mini-monoliths by applying the top tier EDA decoupling approach. So your existing technology strategy is able to be retained and extended without doing anything extreme, and without new spend. The middle tier, then, is a set of bounded contexts that can be thought of as mini-monoliths, connected (where necessary) via the top tier approach.
I'll get to the low tier shortly.
Tech Talent
| [T]he best programmer doesn’t add ten times the value. She adds more like a hundred times.2 |
Perhaps you've experienced or are experiencing growth, and as Steve Jobs is oft quoted as having said: “A players attract A players. B players attract C players”, and oftentimes these organisations have either not understood how to build a talent acquisition approach that enables the bar to remain high (remember, these are people who are increasingly desparate to bring on new resources to assist because they have too much work; even if it's not the right work), so now instead of adding David Lee Roth in the proverbial garage band, you find yourself with Sammy Hagar. That reference certainly dates me. 5150 was...serviceable in a pinch, but it was no 1984, which I consider to be an end-to-end masterpiece. Panama, Hot For Teacher, Top Jimmy, Drop Dead Legs, Jump. What a classic. I'm at risk of yet another digression (too late?), which I'm resisting, even if it doesn't seem like it.
| ‘Take our 20 best people away and I tell you that Microsoft would become an unimportant company.’ (-Gates)3 |
Good devs got into software development because they like to solve problems using technology. They love to ship. They love to write code and build stuff. This post claims developers spend "less than 10% of time coding", whereas this one claims they spend 32% of their time "writing new code or improving existing code." I don't necessarily care which one is more correct; both are really sad.
Enabling talent to move at pace is the key. "Moving at pace" (herein) means that developers can work efficiently at their optimal speed when not constrained by external factors beyond their control. This is what is happening in the tech garage bands. There aren't factors beyond their control associated with maturing company processes or dependencies on different groups or teams, or dealing with risks associated with maintaining existing code bases. And (all other things being equal!) startup devs are happier, because they're solving problems and building solutions. They're happier because they're doing the thing they want to do, and the thing they imagined they'd be doing when they decided to become software developers.
The point here is that we'll improve the morale of our devs by enabling them to do more development and less...bullshit non-development. By creating an environment in which your devs can do development, you'll both attract better talent, and retain that talent (this won’t fix your culture, but you get what I mean). And if you can attract A level talent, and they hire A level talent, then you'll need less developers, and you'll achieve both higher speeds and better quality. Create the right cycle for success by prioritising the satisfaction of your most important asset: humans.
How Does EDA Help?
This is the low tier from my original diagram. Because with EDA you have eliminated (or come as close as you possibly can) dependencies, you can take that pattern applied at the highest level of the technology tiers and apply it to the lowest tier, which is to say within an individual project architecture using EDA, then you've effectively decoupled the work within a project, so that an individual developer gets to truly move at pace! They can go as fast as they can go, without dependencies. It's just the same pattern applied again and again, at increasingly more detailed grains.
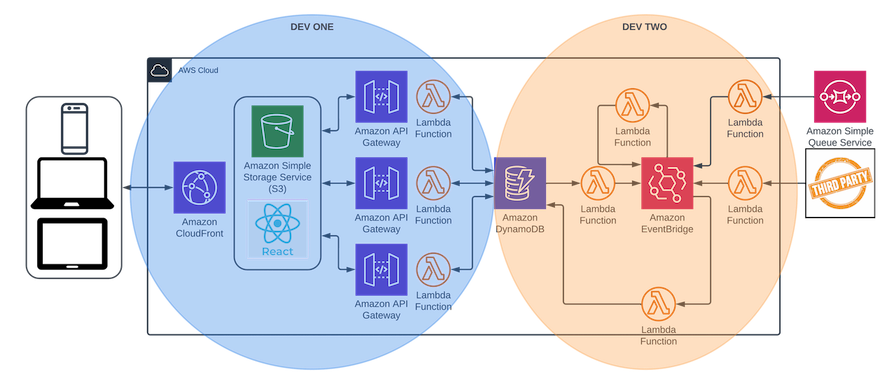
Let's take a look at a more detailed project diagram to drive the point home.
Here, we have a fictitious initiative, which is a basic web application. I won't get deep into what technologies are used, but I'll talk about some of the roles of the different services. For the UI, imagine we're building it in React so it's dynamic mobile/web, and we're hosting it on a static S3 bucket, fronted by CloudFront. Basic and common stuff.
Behind that, we're using DynamoDB in this fictitious example, and applying patterns of backend-for-frontend (BFF), single-table-design. I'm a huge proponent of this approach, even if it's not at all relevant to this conversation. Side note: I wish single-table-design wasn’t STD because I think I’d laugh if I said “BFF” and “STD” together, especially in a work setting. Anyway, I include mention of that approach here so that the architecture resembles a real application design. Importantly, the dev who is developing the UI is the one responsible for accessing the data within DynamoDB. She has total and complete control, which means we've eliminated all dependencies, and this allows her to work at pace.
Our other dev is responsible for the backend (our fictitious initiative is important and it's large, but it only takes two to deliver it). She has implemented a Lambda function to drain a queue (perhaps obtaining data from a disparate system in our overall ecosystem, following our earlier discussion), and she built an integration with a third party, which is an hourly GET RESTful API call that the system needs to make. She publishes everything into a messaging hub (enabling multi-subscriber, event replays, and other benefits), and further is responsible for loading the BFF with data from each. She, too, is working in (good!) isolation, because the system is correctly decoupled.
The Right Tool for the Job
If you are a startup, then your bounded contexts can all individually follow the same EDA pattern, if that makes sense for you, and everything else I've stated here remains exactly the same. But they don't have to be. Remember back in the day when we worked for companies who would buy a server and if we wanted to do something else, we had to convince someone to get us another server to install our something else on? I think about those days as having a hammer and begging those-who-control-the-purse-strings to buy us a screwdriver. And as we all know, if all you have is a hammer, everything looks like a nail.

This is such an empowering capability, especially when coupled with the unlock of the cloud. Gone are the days in which we have to buy a new server to stand up some sort of new technology stack. And with an implementation of the EDA at a bounded context level, you can apply this to all areas of your technology stack. Your bounded context can be a different architecture. It can be a different technology stack. It can have different patterns and different concepts. It's all about creating opportunities through creating flexibility.
Want to have speed? Remove obstructions. Decouple your architecture, and choose the right tool for the job, every time.
Cloud Agnosticism and Cloud/On-Prem Hybrids
I've written in the past about how being cloud agnostic is not only bullshit for 99% of companies out there, it's actually a goal that is detrimental to the organisation (minimally, there’s a huge trade-off).
In part, it's because traditional approaches to becoming cloud agnostic equated to leveraging open source technologies, or 3rd party technologies and frameworks where cloud-native solutions were available. The reason I disagree with doing this is because I forego all of the benefits that the cloud offers. Since we've talked at some length about DynamoDB, let's continue with that. An alternative (non AWS cloud-native) NoSQL database would be Cassandra, which I have nothing negative to say about, all things being equal, and going with Cassandra means I could (theoretically, at least) deploy it equally in Azure or AWS, for example. That's a good thing, on its surface, but what do I give up in doing so?
Alternatively, Amazon DynamoDB is a fully managed NoSQL database service provided and maintained by AWS, designed to offer fast and predictable performance with seamless scalability. When you use DynamoDB, AWS handles several critical aspects on your behalf, such as server and infrastructure maintenance, ensuring high availability and durability, and automatically replicating your data across multiple AWS Regions to provide built-in fault tolerance. This eliminates the administrative burden of operating and scaling a distributed database, as AWS takes care of hardware provisioning, setup, configuration, and patching. Additionally, DynamoDB offers built-in security features, backup and restore options, in-memory caching (DAX), and real-time data streaming capabilities (DynamoDB Streams), all managed by AWS, enabling developers to focus more on application development rather than database management.
And I can apply this mindset to other services as well. Why would I rather use the pattern of (e.g.) SQS --> EventBridge (EB) instead of, for instance, Rabbit MQ? On the surface, RabbitMQ gives me multi-subscriber, and it's a queue, so theoretically it's better because it's less stuff that can go wrong, but I give up the AWS cloud-native benefits. I just created more liabilities because I have to now write the supporting code to make sure it’s working, etc.
Alternatively, AWS EventBridge is a serverless event bus service that makes it easy to connect applications together. AWS handles the infrastructure, scaling, reliability, and maintenance. This is in contrast to RabbitMQ, a message broker that requires you to manage the deployment, scaling, and maintenance of the software and the underlying infrastructure. With RabbitMQ, you're responsible for managing the message queues, ensuring high availability, and handling failovers, whereas with EventBridge, AWS abstracts these complexities. EventBridge offers native integration with various AWS services and SaaS applications, allowing for a more seamless and scalable event-driven architecture without the overhead of managing the underlying infrastructure, unlike RabbitMQ which generally requires more manual setup and maintenance for integration and scalability.
The point here isn’t to bash Cassandra or RabbitMQ, both of which I’ve never had any problem working with; I’m contrasting it to what tradeoffs I get from a cloud-native alternative. Rather, instead of foregoing the open source (or non-cloud managed service) route, you could use Eventbridge on the AWS side and Event Grid in Azure (their version of the message broker, if I’m not mistaken). Our highest level bounded contexts could actually be different clouds. Or on-prem. Or a hybrid of each. And if we think about the projects and the clouds they're executing in as extensions of our bounded contexts, then it follows the same pattern. While I still don't believe in being cloud agnostic (for the 99%, and unless you're Meta or Netflix, you're not the 1%), I can now see a viable path to which you can have multiple clouds in play at any given time, and they can work together, because of the top tier connectors. At least you can achieve cloud independence, while exploiting all the cloud-native offerings without being held hostage by a single platform. I actually think that's far better than being cloud agnostic.
Organisationally
This is the point of an entirely different post, but one thing does need to be mentioned here, and that is that the biggest reason that m*croservices fail is not because of the technologies or the people, but because of Conway's Law, which states "organizations which design systems (in the broad sense used here) are constrained to produce designs which are copies of the communication structures of these organizations."
If you end up having (human) resources that span the maintenance and extension of bounded contexts, those resources are going to end up incorrectly combining disparate projects. Your organisational structure will undo the top tier, and it's the main reason that microservices and macroservices alike fail, but it's not talked about enough, and I do not think it is appreciated/understood at all. Pretty insane to think about it: the number one cause of m*croservices failing is Conway's Law, and yet it's never discussed at the strategic technology level. And if you don't start to respect it, it's going to ruin your best intentions and best laid plans, too.
Conclusion
Wow. I finally got there, with multiple pints in my rear view mirror and my family long in bed.
Quick recap: as a practical means toward accomplishing the goal of decoupling, the focus needs to be on how data is accessed and shared. This means accomplishing the ultimate goal of decoupling is really about the connections between disparate code bases, whether they be old or new, LAMP or request/response, GCP or AWS. It could be how legacy code integrates with new code bases or how new solutions integrate together, internal integrations or with third parties, and everywhere in between.
The individual solutions, whether they be stand-alone applications or internal upgrades of existing functionality, can and should be developed using the best technologies and approaches available, and that is a very project-by-project set of decisions. This allows them to be built at pace, and to be built in the most optimal ways (creating the best solutions and limiting dependencies to things within their own control), which is the holy grail of enterprise system integrations. It's enabled through focusing on the connections and assuring those follow a set of patterns. The overall system can (and I'm arguing should) be event driven because it governs the rest, but the individual applications can be legacy or built using something different, when there is reason, so long as the macro/holistic parts (the mini-monoliths, or macro-services) adhere to the right set of connection patterns between them.
That's the secret sauce, and it's why adhering to (and remaining focused on retaining) the right connections between the parts matters so much.
It allows the most precious resource an organisation has (the talent) and focuses them on new and interesting work, which has the tangential benefit of improving morale, increasing employee engagement and ownership, and generally creating the ideal cycle from a high performing culture standpoint.
This is why I'm a stickler for details on architectures, and details on team organisations, and other things that usually make me sound like I'm a dick or like I’m a pedantic purist. In real life, it's grounded in strategic thinking, or at least that’s what I tell myself.
References
1Dylan, B., 2005. Bob Dylan chronicles : Volume one. Leicester: W F Howes.2Hastings, R. & Meyer, E., 2020. No rules rules: Netflix and the culture of reinvention, London, UK: WH Allen.
3Collins, J.C., 2020, pg. 13. Beyond entrepreneurship 2.0, London, UK: Random House Business Books.
4Brooks, F., 1995. The mythical man-month. Reading: Addison-Wesley.
Categories: Technology, Architecture, Strategy Tags: #eda, #strategy



